I recently had the pleasure of working with the great team at Chameleon to migrate to AWS lambda and API Gateway. The primary goal was to geographically route users to the closest region for the lowest latency possible. One important requirement was that the files served to client websites must be real-time and not cached so customers could see their changes immediately.
We tried this using only API Gateway and Cloudfront, but AWS limitations with custom domains made that impossible. According to posts on the AWS Forums, these are likely to be resolved in the near future, but we needed an alternate strategy. You can go straight to our haproxy Solution or read on to learn more about why this was necessary.
The Goal: Faster Delivery
Chameleon allows customers to build and optimize product tours without code. The targeted tours run inside the customer app or site and are optimized for customer conversion and retention.
Growing quickly and committed to the fastest possible user experience, they wanted to move to a scalable AWS solution to deliver client-side Javascript. We settled on a serverless architecture of API Gateway and Lambda because it wouldn't require maintenance of EC2 instances or Elastic Beanstalk.
Using claudia.js to deploy the Node.js function to lambda and wire up API Gateway is a straightforward task. I extended this via a shell script to deploy to multiple regions and all was well. We had their Node function running in multiple regions with built-in management of lambda versions and API Gateway stages.
The Problem: Global Latency
Unfortunately, at present AWS provides no mechanism to route to API Gateway in the region closest to the user.
The crux of the problem is that API Gateway is SSL only and requires the HTTP host header and the Server Name Indication (SNI) to match the hostname requested. Since you can only use a custom domain name in one region, each API region must have a unique custom domain name. The primary hostname used to load balance will mismatch the region chosen for many, if not all, users.
https://fast.trychameleon.com is the URL that serves the Javascript.
When the browser sends the request, it sends the Host header:
> Host: fast.trychameleon.com
It also sends the SNI with the same hostname. Even if we use fast.trychameleon.com in one region as the custom domain name, we can't use it again and the requests will fail in the other regions with mismatched host names.
In A Perfect World: Latency-Based DNS Routing
Here's an illustration of a solution that does not currently work (I'll explain why in a moment).
Ideally, we'd like to do something simple like this:
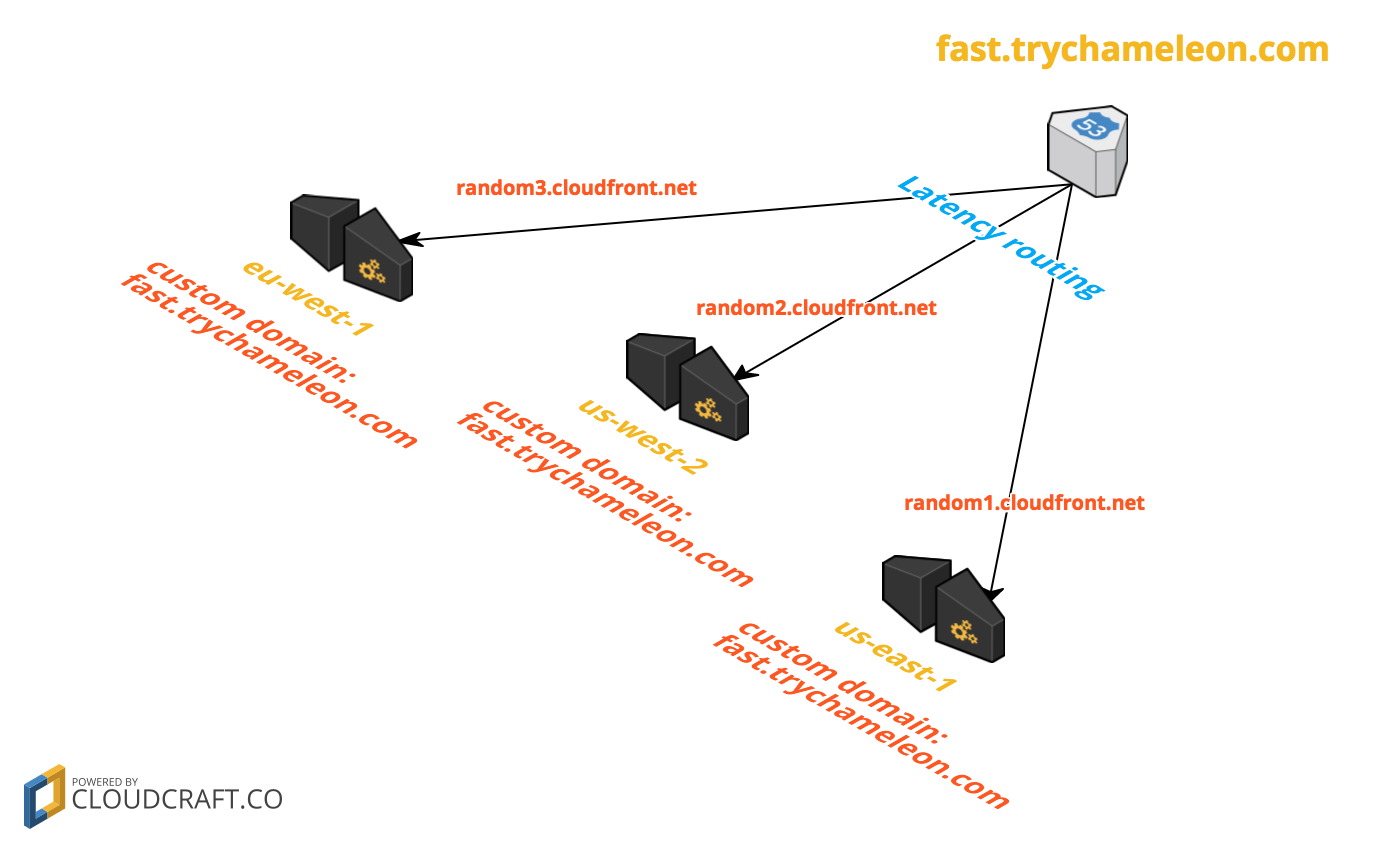
If we could reuse the same custom domain, we would add one in each region for fast.trychameleon.com. The SSL cert for this hostname or a wildcard *.trychameleon.com would work in this scenario.
We would also set up a CNAME with latency routing for every region in Route53 where fast.trychameleon.com has a value of the cloudfront domain assigned to each API Gateway like random1.cloudfront.net.
The DNS records might look something like this:
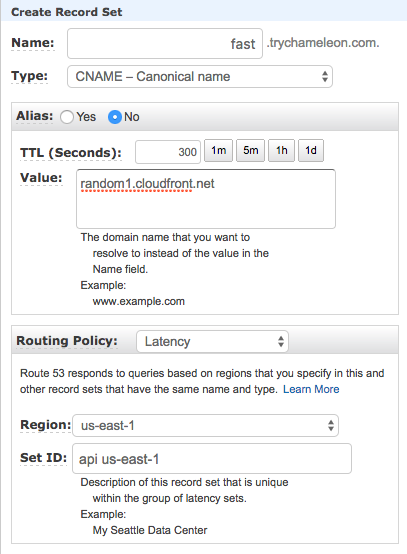
Route53 would check latency and return an IP for the closest API Gateway Region. That region would have fast.trychameleon.com as a custom domain name, the Host header and SNI would match, and API Gateway would return content from the endpoint.
Why Routing Directly to API Gateway Doesn't Work
When you create a custom domain name for API Gateway, AWS creates a CloudFront distribution with the API in that region as an origin.
AWS does not allow a domain name to be associated with more than one CloudFront distribution.
Going back to our original scenario, you have to set different custom domain names for each of your API Gateway regions. If you try to add a domain name you've already used, you'll get this error:
The domain name you provided is already associated with an existing CloudFront distribution. Remove the domain name from the existing CloudFront distribution or use a different domain name. If you own this domain name and are not using it on an existing CloudFront distribution, please contact support.
Your browser will always send the Host header and SNI you requested, fast.trychameleon.com. So no matter what custom name you give your custom domains, if they are not the primary domain the customer is requesting, you will get a 403 Forbidden from CloudFront or an SSL handshake error:
< HTTP/1.1 403 Forbidden
< Date: Thu, 03 Nov 2016 22:57:43 GMT
< Content-Type: application/json
< Content-Length: 23
< Connection: close
< x-amzn-ErrorType: ForbiddenException
< x-amzn-RequestId: 1234-5678-9101112-1314
< X-Cache: Error from cloudfront
< Via: 1.1 12345678.cloudfront.net (CloudFront)
< X-Amz-Cf-Id: 1234-5678==
<
* Closing connection 0
{"message":"Forbidden"}
Other Attempts
We considered some other possibilities, but none met our criteria.
-
Create a CloudFront Distribution with the API Gateways in each region as origins
CloudFront will choose the first origin that matches the behavior precedence. So you will always get a response from the same region, not the closest one. And you still have the SNI/host mismatch issue.
-
Redirect the user.
Set up an endpoint that is cached by CloudFront and returns a 302 redirect to the URL of the API closest to the user. The cost is at least one more DNS lookup and an extra roundtrip.
-
Use one API as the origin to a new CloudFront distribution.
We get the advantage of geolocation at the edges, but it requires caching responses.
None of these are ideal for speed and live data. So we arrived at a different solution.
The Solution
Ultimately we concluded that a proxy could send the right header and SNI information at the lowest cost. haproxy is ideal as a fast and highly memory- and CPU-efficient option.
The upside is that we get the benefits of geolocation and are guaranteed to serve the current version of customer data. The downside is that we aren't serverless anymore and have to maintain some instances with failover. This was an acceptable tradeoff to try and achieve responses under 200ms.
Here's our current architecture that follows the AWS complex DNS failover model:
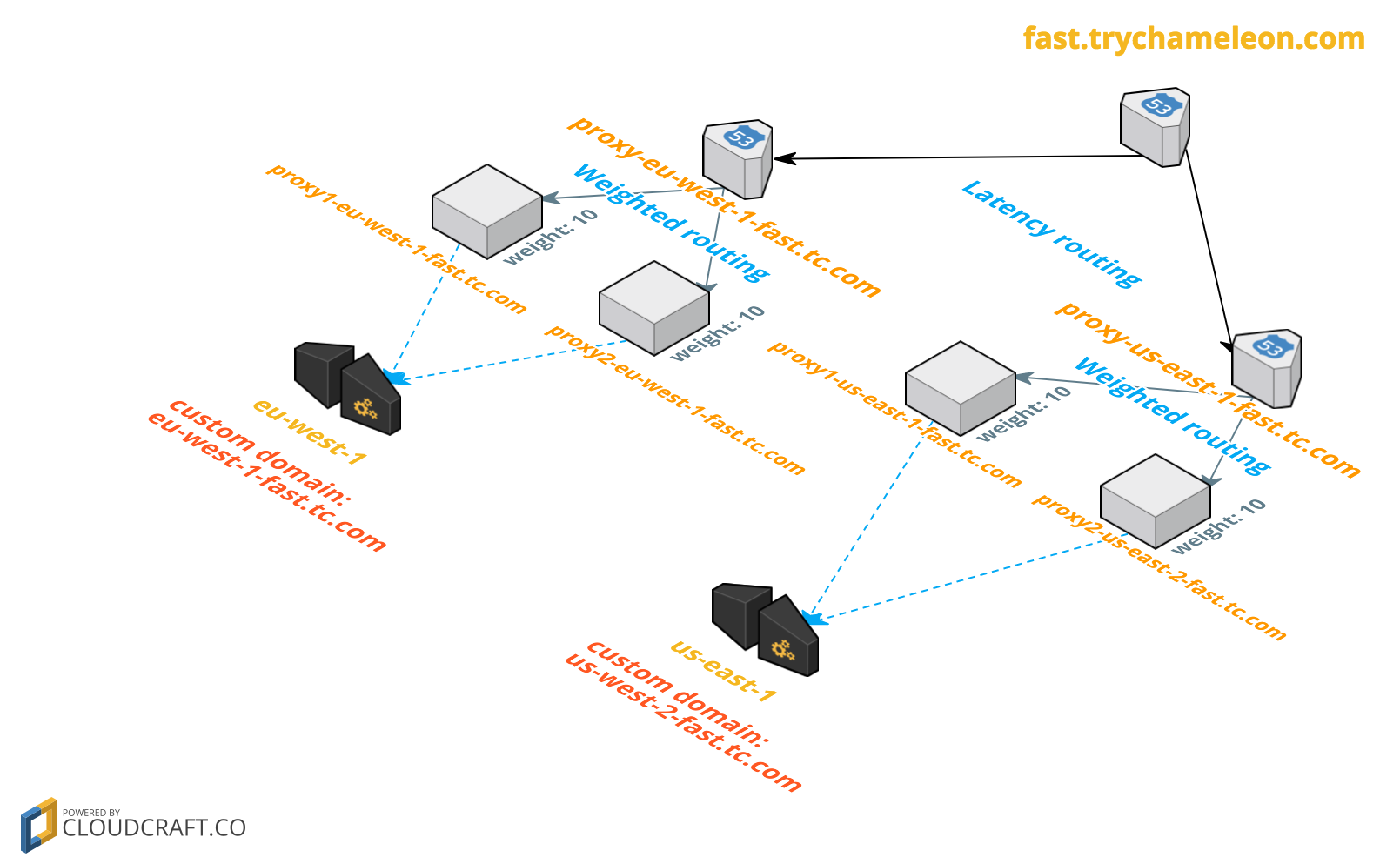
This only shows 2 regions but could be expanded to as many as needed. Here's how it works for a user in New York (us-east-1):
fast.trychameleon.comis the initial DNS lookup.- Route53 returns the resource record for the closest of the two latency routed hostnames:
proxy-us-east-1-fast.trychameleon.com - The next DNS lookup for
proxy-us-east-1-fast.trychameleon.comwill return one of the equally weighted haproxy instances at eitherproxy1-us-east-1-fast.trychameleon.comorproxy2-us-east-1-fast.trychameleon.com. The DNS records look like this:
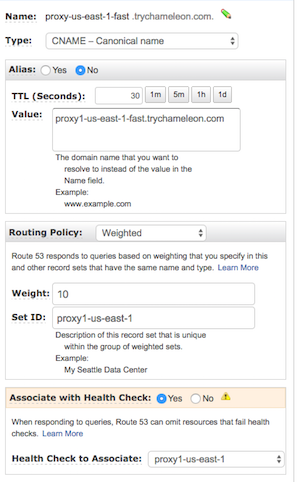
Notice the health check for the instance value, which is critical to failover.
proxy1-us-east-1-fast.trychameleon.comis a CNAME associated with the haproxy instance. That's where the browser will send the request.
If one haproxy instance is down, the health checks will cause DNS to failover to another instance in the region. If all haproxy instances are down in a region, the DNS latency check will failover to another region.
Each haproxy instance in a region is configured to send requests to the same backend, and to modify the headers accordingly. This snippet from the haproxy.cfg ansible template sends the correct information to the API Gateway:
frontend https
bind *:443 ssl crt /path/to/ssl/certificate.pem
mode http
http-request deny if !{ ssl_fc }
option forwardfor
default_backend api_gateway
backend api_gateway
mode http
option httpclose
http-request replace-value Host .* {{ backend }}
server apig1 {{ backend }} ssl sni str({{ backend }})
{{ backend }} is dynamically replaced by ansible when the config is deployed. The bold portion sends the API Gateway the custom domain name it expects, so {{ backend }} becomes us-east-1-fast.trychameleon.com in this case:
http-request replace-value Host .* us-east-1-fast.trychameleon.com
server apig1 us-east-1-fast.trychameleon.com ssl sni str(us-east-1-fast.trychameleon.com)
Important note: Use the same subdomain for all components so that wildcard SSL certs will work. All of these hosts are in the trychameleon.com domain.
With a basic lambda function, we can now achieve responses under 200ms and in many cases as low as <50ms.
How AWS Can Fix It
If AWS allowed the same CNAME multiple in multiple API Gateway regions, we could use the original latency-based routing outlined in the first section above. According to AWS forum threads like this one, it's on the roadmap.
Either way, hopefully this post has solutions that you can use in your systems, particularly if you are forced to use SSL for haproxy backend servers that require SNI.